AIコードレビューの選び方と運用設計

この記事は、チーム開発の標準化で扱った4階層のうち、レビュー層を深掘りするものです。
AIでコードが速く大量に出るほど、レビューが詰まります。GoogleのDORAレポート2025年版も、生成が増えるほど既存のレビューや配信の仕組みが追いつかなくなると指摘しています。だからこそレビューを自動化し、人は判断に集中する設計が要る。ただし、ツールを入れれば解決、とはいきません。何を選び、どう運用するかで結果が大きく変わります。
この記事の対象読者
- AIコードレビューの導入を検討しているCTO・技術リード
- 人手レビューの往復が増え、設計議論の時間を奪われているチーム
- Copilot・CodeRabbit・Greptile・Codexの違いと選び方を、宣伝でなく実データで知りたいエンジニア
まず知るべき事実:検出率と誤検知はトレードオフ
ツール選びの前に、全ツールに共通する性質を押さえる必要があります。たくさん拾うツールは、その分だけ誤検知も増える。逆に、静かなツールは見逃しが増える。これは設定の良し悪しではなく、感度と精度の本質的なトレードオフです。
ある独立した実測(8ツールを1つのプルリクエストで試した記事)が、これを端的に示しています。意図的に3つのバグ(重大1・中1・軽微1)を埋め込んだPRをレビューさせたところ、コードベース全体を索引するGreptileは6件拾った一方で誤検知も6件。要約重視のCodeRabbitは拾いは2件と少なく誤検知は6件。GitHub Copilotは誤検知1件と静かでしたが、埋め込んだバグをほぼ拾えませんでした。そして重大なバグ(クラウドのリージョン未指定)は、どのツールも拾えなかったのです。
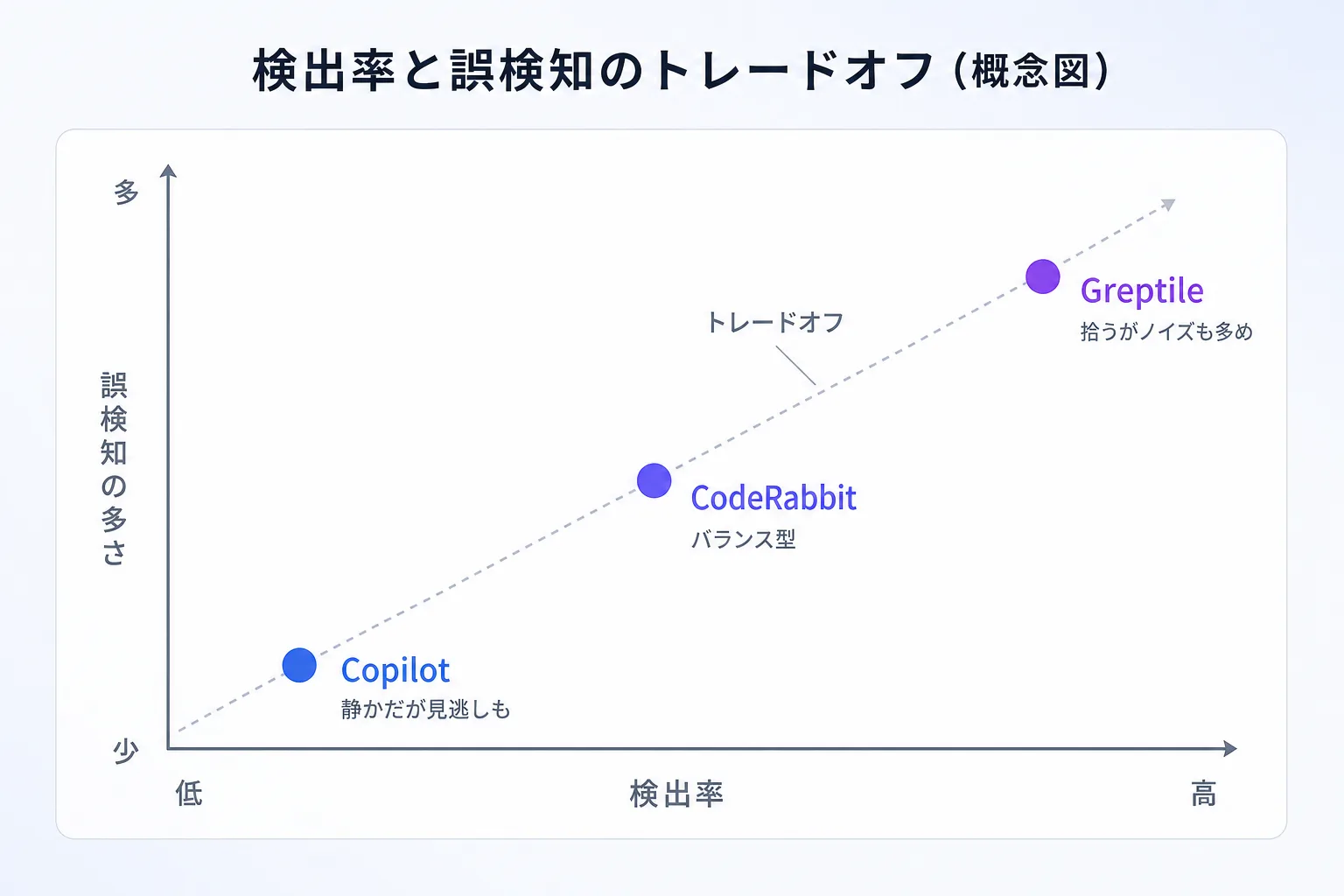
1つのPRでの第一印象なので断定はできませんが、傾向ははっきりしています。この背景には、従来の静的解析でもCI上の検出の8〜9割が誤検知や無関係という長年の課題があり、AIレビューも油断するとこの「ノイズで埋もれる」状態に陥ります。だから問いは「どれが一番賢いか」ではなく、自社の許容できるノイズ量と、拾ってほしい問題の種類は何かになります。
4ツールの性格
AIコードレビューに万能の一択はありません。代表的な4つの性格は次の通りです。検出品質の列は、後述するベンチマークの注意点を踏まえて読んでください。
| ツール | 文脈の捉え方 | 性格 | 向いているチーム |
|---|---|---|---|
| GitHub Copilot | 差分中心(関連ファイルも探索) | GitHubネイティブで設定が軽い。速いが浅め、静かだが見逃しも | GitHub中心で設定を増やしたくない |
| CodeRabbit | PR中心 | 導入が速く要約やlint連携が広い。簡潔だが誤検知の指摘もある | 複数プラットフォーム・予算重視 |
| Greptile | リポジトリ全体を索引(RAG) | 差分の外の依存まで踏まえる。拾うが誤検知も多めになりがち | 大規模で相互依存の強いコードベース |
| OpenAI Codex | エージェント実行環境に依存 | 生成と同じ流れにレビューを組み込める。単体製品ではない | 生成からレビューまで一気通貫にしたい |
Greptileがリポジトリ全体を索引して差分の外にある依存まで踏まえるのは強みですが、静的解析の土台を持たずLLMの推論に頼るため、構造的に誤った提案も起こり得ます。Copilotはゼロ設定でGitHubに溶け込み、提案をその場で適用できる手軽さが利点ですが、深さより速度に寄せた設計です。どちらが良い悪いではなく、性格が違います。
ベンチマークの読み方:独立かベンダーか
各社が「検出率No.1」を掲げますが、数字は出典で読み分ける必要があります。判断の鍵は、誰がどんなデータで測ったかです。
- 最も信頼できるのは独立した実測。2026年に公開されたMartianのCode Review Benchは、17のツールを20万件超の実際のプルリクエストで評価し、開発者が実際に直した指摘の割合(=有用さ)で測ります。データも手法も公開され、再現できます。
- ベンダーが自社の都合で出した数字は割り引く。あるツール提供者が公開CVEデータで各社を測った比較では、自社を最高評価(F1約85%)、競合のCodeRabbitを低評価(F1約36%、誤検知が多いと指摘)としていました。測定は公開データセットでも、測定者が当事者なら利益相反があります。
- ベンダーの自己申告(catch rate 82%等)は、小さく自社に有利なデータで取られがち。同じツールでも、独立した測定では数字が下がる例があります。
つまり、特定の1つの数字を鵜呑みにしないこと。複数の独立ソースで傾向が一致する事実(=検出と誤検知のトレードオフ、重大で巧妙なバグの取りこぼし)だけを判断材料にするのが安全です。
選び方の軸
性格とベンチマークの読み方を踏まえると、選定は4つの軸に整理できます。
- 規模と相互依存:コードベースが大きく、変更が他ファイルへ波及しやすいなら、全体を索引するGreptileや文脈探索型のCopilotが向きます。小さく独立した変更が多いなら、PR中心のCodeRabbitで十分です。
- プラットフォーム:GitHub中心で設定を増やしたくないならCopilot。GitLabやBitbucketもまたぐならCodeRabbit。
- 検出重視かノイズ抑制か:取りこぼしを嫌うなら検出重視(Greptile寄り)、レビュー疲れを嫌うなら静かな側(Copilot寄り)。チームがどちらの痛みに弱いかで決めます。
- コストモデル:席課金か、使用量(PR数・トークン)課金か。後述します。
運用設計:ノイズを抑え、指摘を設定に戻す
ツール選びより結果を左右するのが運用設計です。要点は2つ。ノイズを構造的に抑えることと、指摘を設定に戻して育てること。
ノイズを抑える4つの手
- 差分を小さく保つ。大きすぎる差分はモデルが文脈を見失い、表層的な書式指摘に流れます。PRの粒度を小さくするほど、指摘の質が上がります。
- 重大度で絞る。重大度の高い指摘(high・medium)だけを出し、軽微な書式指摘(low)は要約にまとめて行コメントにしない。
- linterと重複させない。formatterやlinterが既に強制している規約は、AIに重ねて指摘させない。役割を分けます。
- 役割で分ける。Cloudflareは、セキュリティ・性能・正しさなど領域ごとに専門のレビューエージェントを走らせ、各エージェントに「何を無視するか」を明示し、最後に1つの優先度付き要約へまとめています。1体に全部やらせるより、ノイズが下がります。
これらは設定ファイルで宣言できます。たとえばCopilotなら `.github/copilot-instructions.md` がレビューの挙動を形づくります。重視する点と無視する点を明示するだけで、ノイズは大きく減ります。
# レビュー方針
## 重視してほしい
- 認可・入力検証・SQLの組み立て(セキュリティ)
- null / undefined の未処理、境界値の取りこぼし
- 仕様(設計書)との不一致
## 指摘しないでほしい
- lint / formatter が既に強制している書式
- 自動生成ディレクトリ(generated/, *.gen.ts)
- 既知の例外(legacy/ 配下の旧インターフェース)
## 出力の形
- 各指摘に重大度(high / medium / low)を付ける
- low の書式指摘は要約に集約し、行コメントにしない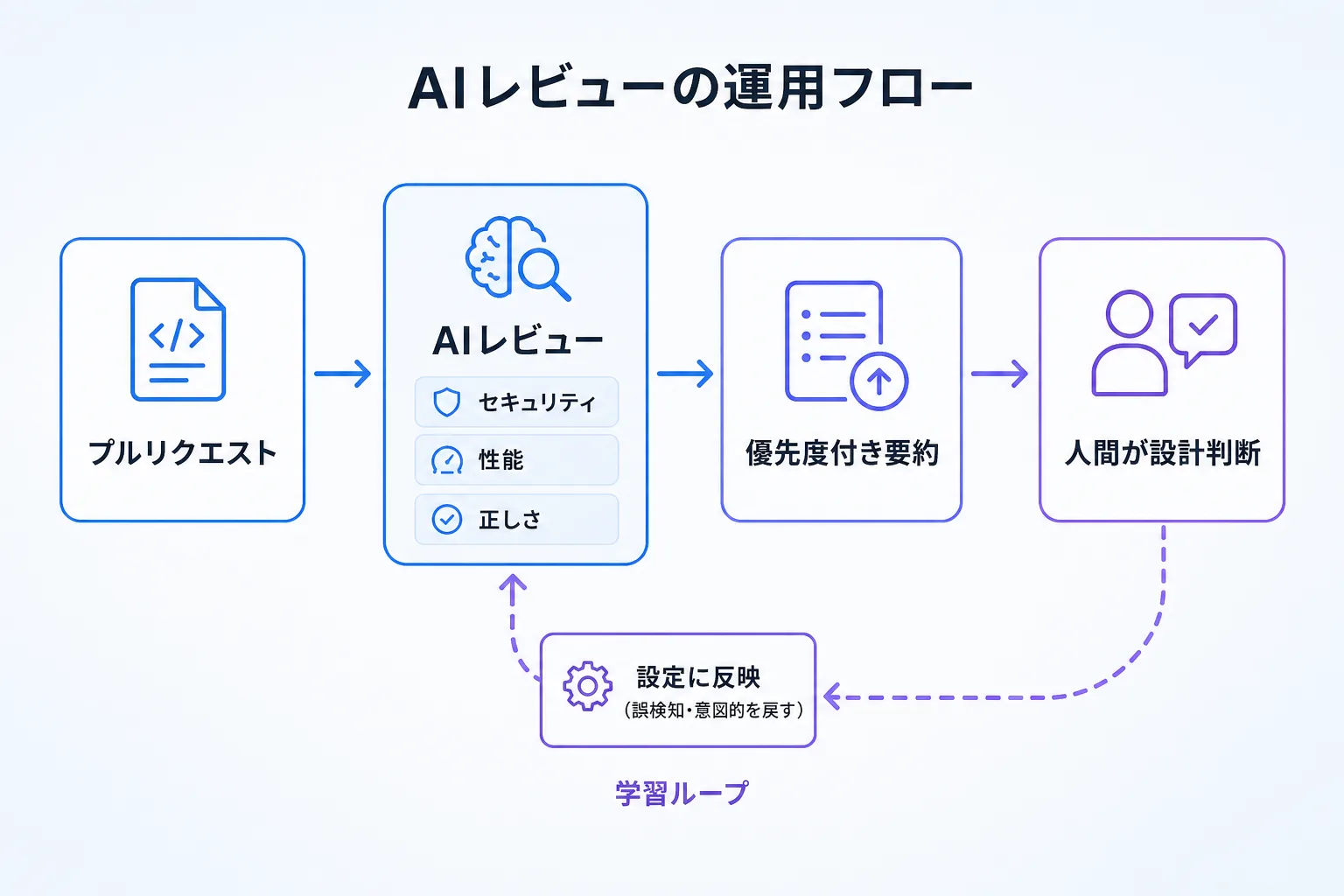
指摘を設定に戻す学習ループ
ツールは入れて終わりにしないことが肝心です。DeNAは、レビューでの指摘をドキュメントや設定に反映し、次回以降のAIの出力品質を上げていく開発体制を公開しています。同じ指摘が何度も出るなら、それは設定に書くべき前提が抜けているサイン。人間が「これは誤検知」「これは意図的」と判断した内容を、設定ファイルへ戻していきます。
私たちの開発では、監査役のエージェントがプルリクエストのレビューを監視し、必要に応じて設定ファイルを自分で更新します。この自立学習と改善のループによって、人手によるレビューを9割ほど削減し、人間の手から離せる範囲を広げながら、人は設計判断に集中できます。レビューが「同じ指摘を繰り返す作業」から「新しい論点だけを見る作業」へ変わっていきます。
コストの考え方
価格は席課金か使用量課金かで性格が変わります。席課金は人数で読めますが、使う人が少ないと割高に。使用量課金はPR数やトークンに連動するため、繁忙期に膨らみます。下表は2026年時点の目安です。料金は頻繁に変わるため、導入前に必ず公式を確認してください。
| ツール | 課金の型 | 目安(2026年時点・USD) | 無料枠 |
|---|---|---|---|
| GitHub Copilot | 席課金(Copilotに同梱) | Pro $10 / Business $19 / Enterprise $39(月) | あり(Free) |
| CodeRabbit | 席課金(開発者あたり) | Lite $12 / Pro $24(開発者・月) | OSS・公開リポジトリは無料 |
| Greptile | 席課金または個別見積 | 公式に明示なし(要問い合わせ。二次情報で約$30との記述あり) | 明確な情報なし |
| OpenAI Codex | ChatGPTプラン同梱+API従量 | Plus $20〜、APIはトークン従量 | 限定的 |
見落としやすいのが隠れコストです。使用量課金のツールは大規模リポジトリで費用が読みにくく、自前のエージェントを組む場合はトークン代が乗ります。席課金でも、premium機能の従量上限を超えると追加課金が発生する型があります。
よくある失敗
1つはノイズで埋もれること。検出重視のツールを無調整で回すと、誤検知が多すぎてレビューが無視されるようになります。これは従来の静的解析で繰り返されてきた失敗で、重大度での絞り込みと「無視する対象」の明示が効きます。
2つ目はベンチマークの数字を鵜呑みにすること。各社の自己申告は条件が有利に設定されがちで、独立した測定では下がることがあります。複数の独立ソースで一致する傾向だけを信じてください。
3つ目はAIに任せすぎること。先の実測で重大なバグをどのツールも拾えなかったように、巧妙な設計上の欠陥は取りこぼします。最終的な設計判断とアーキテクチャの責任は人間が持つ。AIは一次ゲートであり、人の判断を置き換えるものではありません。
まとめ
AIコードレビューは、人手レビューの置き換えではなく、人を設計判断へ振り向けるための一次ゲートです。万能の一択はなく、検出と誤検知のトレードオフを前提に、規模・プラットフォーム・許容ノイズ・コストで選ぶ。ベンチマークは出典で読み分ける。そして効果を決めるのは、ノイズを抑え、指摘を設定に戻す運用設計です。ツール選びは入口にすぎません。
よくある質問
結局どれを選べばよいですか?
万能の一択はありません。大規模で相互依存が強いならGreptile、複数プラットフォームや予算重視ならCodeRabbit、GitHub中心で手軽に始めるならCopilotが入口です。取りこぼしを嫌うか、ノイズを嫌うか、というチームの性質で決めるのが実用的です。
無料で始められますか?
CodeRabbitは公開リポジトリが無料で、小さく始められます。GitHub CopilotにはFree枠があり、既にCopilotを契約していれば追加導入のハードルは低めです。
ベンチマークの「検出率No.1」はどこまで信じてよいですか?
測定者がツール提供者なら割り引いてください。最も信頼できるのは、当事者でない第三者が実際のプルリクエストで測った独立ベンチマークです。1つの数字でなく、複数の独立ソースで一致する傾向を見ます。
誤検知が多いときはどうすればよいですか?
差分を小さく保つ、重大度で絞る、linterと重複させない、設定ファイルで「無視する対象」を明示する、の4つが効きます。人間が判断した誤検知を設定に戻すほど、ノイズは下がります。
人手レビューは不要になりますか?
なりません。定型的な一次チェックはAIに任せられますが、重大で巧妙なバグは取りこぼします。設計判断とアーキテクチャの責任は人間が持ちます。AIは人を判断に集中させるための手段です。
あわせて読みたい

個人のAI活用を組織の成果に変える:チーム開発の標準化
AIコーディングツールを導入しても、個人の使い方に留まればチームの成果にはつながりにくい。設定・知識・レビュー・テストの4階層を共有資産として標準化し、AIが自ら学習・改善するループを回すことで、人は設計と判断に集中できる。その設計手順を具体例とともに解説する。

中小・スタートアップのAI導入が「何から始めるか」で止まる理由|FDEを国内最適化した伴走支援とは
AIを導入したいのに「何から始めればいいか分からない」で止まる。中小・スタートアップに多いこの状態の正体と、海外発のFDE(前線配備型エンジニア)を国内の実情に合わせて作り変えた伴走支援の考え方を、現場の視点で解説します。
AIエージェントが本番で「学ばない」理由 — PoCが止まるのは、AIの賢さの問題なのか
AIエージェントのPoCは動くのに、本番では同じ失敗を繰り返し、精度も上がらない——その原因はAIの性能ではなく、組織の知識が構造化されていないことにある場合が少なくありません。中堅企業の現場診断から、PoCが止まる本当の理由と、諦める前にできることを解説します。