個人のAI活用を組織の成果に変える:チーム開発の標準化

AIコーディングツールの導入は、もはや各社で当たり前になりました。ところが現場でよく起きるのは、メンバーがそれぞれ自己流で使い、チームとしては何も変わらないという状態です。あるメンバーは設定を丁寧に書き、別のメンバーは何も渡さずに使う。同じツールでも、出てくるコードの前提がばらばらになります。
「ツールを入れたのに、思ったほど速くならない」。この戸惑いには理由があります。そして解決の方向も、個人の使い方ではなくチームの仕組みにあります。
結論を先に言えば、効くのは標準化です。それも、設定・知識・レビュー・テストという4つの階層を、チーム全体の共有資産として整えること。この記事では、海外の研究で分かってきた事実と、私たち自身が数名のチームで100体超のAIエージェントを動かしている実体験の両方から、その設計手順を具体的に示します。
この記事の対象読者
- AIコーディングツールをチームに入れたが、効果を実感できていないCTOや技術リード
- 個人での利用から、組織全体への展開へ進めたいエンジニア
- CLAUDE.mdやAGENTS.mdなど、設定ファイルの管理に悩んでいるチーム
ツールを入れただけでは、なぜ速くならないのか
AI研究機関のMETRが2025年に行ったランダム化比較試験では、意外な結果が出ています。平均5年の経験を持つ開発者が、自分が深く関わってきた大規模なオープンソースのリポジトリで作業したとき、AIツールを使うと完了までの時間がむしろ約19%長くなりました。
見逃せないのは、当の開発者たちが作業後に「AIで20%ほど速くなった」と感じていた点です。実測は遅くなっているのに、体感は逆。生産性の感覚は、実際の生産性とずれるという事実が、対照実験ではっきり出たわけです。「速くなった気がする」を根拠に全社展開を決めると、判断を誤りかねません。
なぜ遅くなるのか。条件を見ると理由が分かります。対象は、開発者が隅々まで知り尽くした成熟リポジトリでした。こうした場では、自分で書いた方が速い変更も多く、AIの提案を一つひとつ読み、文脈に合うか確認し、直す手間が、短縮できる時間を上回ります。逆に言えば、不慣れな言語や新規のコード、定型的で量の多い作業ほど、AIの効きは良くなる。どこに使うかを外すと、ツールは時間を奪う側に回るのです。
GoogleのDORAレポート2025年版は、この性質を「増幅器」という言葉で表します。AIは、もともと強いチームの長所をさらに伸ばし、断片化した組織の弱点をかえって露わにする。実際、AIの利用が進むほど個々の作業量(スループット)は増える一方で、チームとしての提供の安定性はむしろ下がりやすい、という関係も報告されました。
理由は単純です。コードが速く大量に生まれるほど、それを検証し、安全に本番へ届けるレビューと配信の仕組みに負荷が集中します。蛇口を太くしても、その先の配管が細いままなら、あふれるのは下流です。個人の生産性向上が、そのままチームの成果になるとは限らない。ここが、ツール導入だけでは速くならない核心です。
だからこそ、AIの使いどころは「人間が得意な作業を速くすること」ではありません。任せられる定型的なタスクをAIへ移し、人間は設計や判断という、人がやるべき領域に集中する。そのためにチーム全体の制御系を整える必要があります。私たちはそれを4階層の標準化として整理しました。
標準化すべきは4階層:設定・知識・レビュー・テスト
国内では、CLAUDE.mdの書き方といった単体のノウハウ記事は増えました。一方で、これらを1つの枠組みとして束ねた整理はまだ少ないと感じます。AIをチームで活かすには、次の4階層をそれぞれ標準化する必要があります。下流ほど、生成量が増えたときの安全弁として効いてきます。
| 階層 | 標準化するもの | 狙い | 代表的な手段 |
|---|---|---|---|
| 設定 | AIへ渡す前提 | 誰が使ってもAIに同じ前提を共有する | CLAUDE.md / AGENTS.md / .claude |
| 知識 | ナレッジの参照可能化 | 属人化した知見をチームの資産にする | Obsidian / 設計書 / ガイドライン |
| レビュー | 品質ゲートの自動化 | 人手を本質的な設計議論に集中させる | Codex / Greptile / CodeRabbit / Copilot |
| テスト | 安定性の担保 | 生成量の増加を安全に保つ | TDD / 仕様駆動開発(Spec Kit) |

設定ファイルをチームの共有資産にする
4階層の起点は設定です。設定ファイルとは、AIに毎回渡す前提を1か所にまとめたもの。これがメンバーごとにばらつくと、同じツールでも出力の質が揃いません。まず、何を書くかの型を決めます。
設定ファイルに書く6項目
良い設定ファイルには共通の構造があります。コマンド、プロジェクト構成、コード規約、レビュー前の確認、そして境界(やってよいこと・要確認・禁止)。中でも効くのがコマンドと境界です。コマンドを正確に書くと、AIは「テストの走らせ方」を毎回探さずに済む。境界を3段階で示すと、勝手に本番設定や秘密情報へ手を伸ばすのを防げます。
# AGENTS.md
## コマンド
- セットアップ: npm install
- 開発サーバー: npm run dev
- テスト: npm test
- 型チェック: npx tsc --noEmit
- Lint: npm run lint
## プロジェクト構成
- src/domain ドメイン(外部依存なし)
- src/application ユースケース
- src/infrastructure DB・外部API
- src/presentation UI・ルート
## コード規約
- ファイルは kebab-case、コンポーネントは PascalCase
- any 型は使わない(unknown + 型ガードで受ける)
- 1ファイル500行・1関数50行を上限とする
## レビュー前の確認
- npm run lint と npx tsc --noEmit が通ること
- 新しいロジックには必ずテストを添える
## 境界(3段階)
- 許可: 既存パターンに沿った実装、テスト追加、リファクタ
- 要確認: 公開APIの変更、依存パッケージの追加、DBスキーマ変更
- 禁止: .env など秘密情報の編集、本番設定の変更一方で、書かない方がよいこともあります。ツールやCIで自動的に強制できる規約は、設定ファイルに重ねて書きません。たとえば「秘密ファイルは編集禁止」を仕組み側(フック)で止めているなら、文章で念を押すより仕組みの方が確実です。設定ファイルは、機械が止められないことを人とAIに伝える場所。役割を分けると、ファイルは短く保てます。
CLAUDE.mdとAGENTS.md、どう使い分けるか
AGENTS.mdは、特定のツールに縛られない設定の共通形式として広がりつつあります。複数のAIコーディングツールが同じファイルを読めるため、ツールを乗り換えても設定を引き継げるのが利点です。実務では、AGENTS.mdを正(マスター)とし、CLAUDE.mdはそこへのシンボリックリンクで揃えるパターンが取りやすい。1つの設定を、複数のツールで使い回せます。
設定はリポジトリの最上位に1つ置くのが基本ですが、サブパッケージごとに固有のルールがあるなら、そのフォルダにも置けます。AIは最も近い設定を優先して読むため、共通ルールは上位に、個別ルールは各フォルダに、と階層で書き分けられます。
設定もGitで管理し、レビューの対象にする
設定ファイルは、コードと同じようにGitで管理します。変更はプルリクエストでレビューし、誰がいつ何を変えたかを追えるようにする。APIキーなどの機密は絶対に書かない、という線引きだけは徹底します。設定がチームの共有資産になると、AIの振る舞いがメンバー間でぶれなくなり、設定の改善がそのままチーム全員の生産性に乗ります。
AIに任せられる範囲を広げる:自立学習と改善のループ
設定を共有資産にすると、次の一手が見えてきます。レビューでの指摘を、設定側へ戻すことです。DeNAは、レビューで見つかった指摘をドキュメントや設定に反映し、次回以降のAIの出力品質を上げていく開発体制を公開しています。同じ指摘が二度三度と出るなら、それは個人の注意ではなく、設定に書くべき前提が抜けているサインです。
ループはこう回ります。レビューで定型的な指摘が出る → その指摘を設定やガイドラインに追記する → 次回からAIがその前提を踏まえて出力する → 同じ指摘が出なくなる。一度設定に取り込めば、人間が毎回確認しなくてよい範囲がそのぶん広がります。レビューは「同じ誤りを指摘し続ける作業」から「新しい論点だけを見る作業」に変わっていきます。
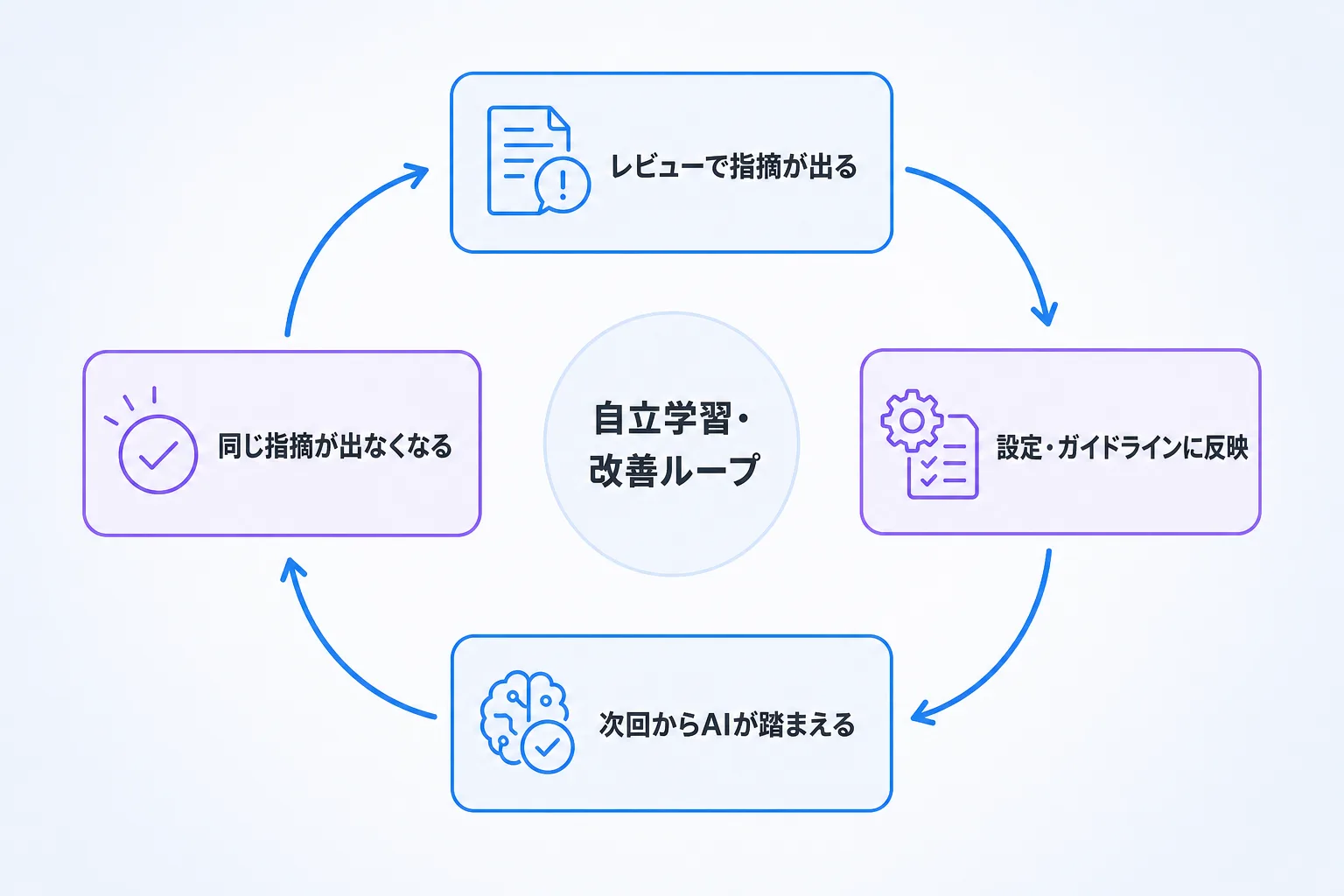
私たちの開発でも同じ考え方を採っています。社員は数名ですが、100体を超えるAIエージェントが動いており、監査役のエージェントがプルリクエストのレビューを監視して、必要に応じて設定ファイルを自分で更新します。AIが自分で学習し改善するループを回すことで、人間の手から離せるタスクが着実に増え、人は設計や意思決定に時間を使えます。AIは人の作業を肩代わりして終わりにする道具ではなく、人が創造と判断に集中できる環境を整える手段だ、ということです。
外部レビューの自動化:ツールの選び方
改善ループを回す土台として、AIによるコードレビューを組み込みます。ツールは複数あり、性格が異なります。ファイルをまたいだ文脈の把握に強いもの、広く普及していて導入が容易なもの、GitHubにネイティブで設定がほぼ不要なもの。選ぶ軸は2つです。プルリクエストの粒度(小さく刻むか、大きくまとめるか)と、既に使っている開発基盤との相性。詳しい比較は別記事にまとめています。
私たちの場合、レビューにAIを組み合わせたことで、人手によるレビューを9割ほど削減し、エンジニアは設計判断に時間を使えるようになりました。重大な指摘の発生率も、標準化前の82%から40%未満まで下がっています。数字そのものより、指摘の質が「些末な書き方」から「設計の妥当性」へ移ったことが、実感としての変化でした。
安定性を守る:テストと仕様駆動の統一
DORAレポートが指摘した「安定性が下がりやすい」という弱点は、4階層の最下層で受け止めます。テストとバージョン管理を強くすれば、その弱点は逆手に取れます。生成量が増えても、確かなテストがあれば安全に出荷できる。私たちも、当初はメンバーごとにばらついていたテスト駆動開発をチームで揃えたことで、品質が安定しました。テストの型が揃うと、AIに「このテストを通すコードを書いて」と任せやすくもなります。
仕様を一次成果物に置く仕様駆動開発(GitHubのSpec Kitなど)も2025年に広がりました。何を作るかを先に固めてから、AIに作らせる。仕様を起点にすることで、生成が目的からずれるのを防ぎ、レビューでも「仕様どおりか」という明確な基準で見られます。
よくある失敗:設定ファイルの肥大化と形骸化
設定を整えるほど、つい盛り込みすぎてしまいます。しかしAnthropic自身も、設定ファイルは簡潔に保つよう勧めています。情報を詰め込みすぎると、AIが踏まえるべき前提が膨らみ、肝心のルールがかえって無視されやすくなるからです。人間が長い規約書を読み飛ばすのと同じことが、AIにも起きます。長くなったら別ファイルに分け、必要なときだけ参照させる形にします。
もう1つの失敗は、誰が設定を保守するのかを決めないことです。担当とレビューの流れが曖昧だと、設定はすぐ古くなり、形だけのものになります。書いた当初は正しくても、コードが変われば設定も古びる。更新の仕組みごと標準化することが、形骸化を防ぎます。前述の改善ループは、この保守を人手から仕組みへ移す試みでもあります。
まとめ
AIツールの導入は出発点にすぎません。本当に効くのは、設定・知識・レビュー・テストの4階層を共有資産として標準化し、AIが自分で学習し改善するループを回すことです。研究が示すとおり、AIは増幅器であり、土台が整っているチームほど大きく伸びます。これにより、人間は本来集中すべき設計や判断に時間を使えるようになります。
まず着手しやすいのは、設定ファイルの標準化とGit管理です。先に示した6項目を骨格に、自社のコマンドと境界から書き始める。そこからレビューの自動化、テストの統一へと下流に広げていくと、AIを使うほどチームが強くなる状態に近づきます。
よくある質問
CLAUDE.mdとAGENTS.md、どちらを使うべきですか?
特定のツールに縛られたくないなら、共通形式のAGENTS.mdを正とするのがおすすめです。CLAUDE.mdはそこへのシンボリックリンクで揃えると、1つの設定を複数のツールで使い回せます。サブパッケージ固有のルールは、そのフォルダにも設定を置けば、AIが近い方を優先して読みます。
設定ファイルには何を書けばよいですか?
コマンド、プロジェクト構成、コード規約、レビュー前の確認、境界(許可・要確認・禁止)の6項目が骨格です。逆に、ツールやCIで自動的に強制できる規約は重ねて書かないでください。簡潔さが守られ、肝心のルールが読まれやすくなります。
.claudeディレクトリはGitにコミットすべきですか?
はい。設定はコードと同じく共有資産なので、Gitで管理しレビュー対象にします。ただしAPIキーなどの機密や、各自の環境に依存する設定は含めず、別の安全な場所で管理してください。
AIコードレビューツールはどれを選べばよいですか?
プルリクエストの粒度と既存の開発基盤との相性で選びます。ファイルをまたいだ文脈が重要なら文脈把握に強いもの、まず手軽に始めたいならGitHubネイティブのものが候補です。
AIを使うとむしろ開発が遅くなるというのは本当ですか?
条件によっては起こり得ます。METRの研究では、熟練者が知り尽くした領域で個人的に使うと遅くなる例が示されました。一方、不慣れな領域や定型的で量の多い作業では効きます。チームで標準化し、AIに任せるべきタスクへ向けることで、人間は設計や判断に集中できます。
AIの設定ファイルは誰が保守するのですか?
保守の担当とレビューの流れを決めることが重要です。私たちは監査役のエージェントがレビューを監視し、必要に応じて設定を自動更新する形にして、属人化と形骸化を防いでいます。
あわせて読みたい

AIコードレビューの選び方と運用設計
AIコードレビューは検出率と誤検知がトレードオフで、万能の一択はない。Copilot・CodeRabbit・Greptile・Codexの性格、独立ベンチマークの読み方、ノイズを抑える運用設計までを、出典付きの実データで解説する。

中小・スタートアップのAI導入が「何から始めるか」で止まる理由|FDEを国内最適化した伴走支援とは
AIを導入したいのに「何から始めればいいか分からない」で止まる。中小・スタートアップに多いこの状態の正体と、海外発のFDE(前線配備型エンジニア)を国内の実情に合わせて作り変えた伴走支援の考え方を、現場の視点で解説します。
AIエージェントが本番で「学ばない」理由 — PoCが止まるのは、AIの賢さの問題なのか
AIエージェントのPoCは動くのに、本番では同じ失敗を繰り返し、精度も上がらない——その原因はAIの性能ではなく、組織の知識が構造化されていないことにある場合が少なくありません。中堅企業の現場診断から、PoCが止まる本当の理由と、諦める前にできることを解説します。